Introduction
Each musical instrument has its own characteristic sound due to the contributions of different harmonic intervals above the fundamental frequency. The relative strengths of these harmonics are due to the mechanism of sound production and transmission of the instrument. For my project, I modeled the sound generation of two musical instruments, the harpsichord and clavichord. Building upon content in the class text (Giordano and Nakanishi, specifically chapters 6 and 11), I simulated the plucking action of the harpsichord for different values of several input parameters, compared computational results to data from a real instrument, and designed and executed a computational model for the clavichord.
Mathematical Background
For both instruments, the initial wavefronts evolved in time via
![\\y(i,n+1)=2[1-r^2]y(i,n)-y(i,n-1)+r^2 [y(i+1,n)+y(i-1,n)]](https://pages.vassar.edu/magnes/wp-content/ql-cache/quicklatex.com-ffd3eb243af269e0d849ddefbe6bbb88_l3.png "Rendered by QuickLaTeX.com")
where i is the spacial index of the wire’s height y, n is the temporal index,  , Δx is the spacial step size, and Δt is the time step size. The parameter c is the speed of the wave on the string, and relied on several parameters of the string via
, Δx is the spacial step size, and Δt is the time step size. The parameter c is the speed of the wave on the string, and relied on several parameters of the string via

where T is the tension on the string, R is the radius of the string, and ρ is the density of the string material. The final key equation needed is for the tension:

where L is the length of the string and  is the fundamental frequency of the note desired. It should also be noted how to calculate the force of the string on the bridge (where sound is transmitted to the soundboard and then the air) using eq. 11.4:
is the fundamental frequency of the note desired. It should also be noted how to calculate the force of the string on the bridge (where sound is transmitted to the soundboard and then the air) using eq. 11.4:

Harpsichord
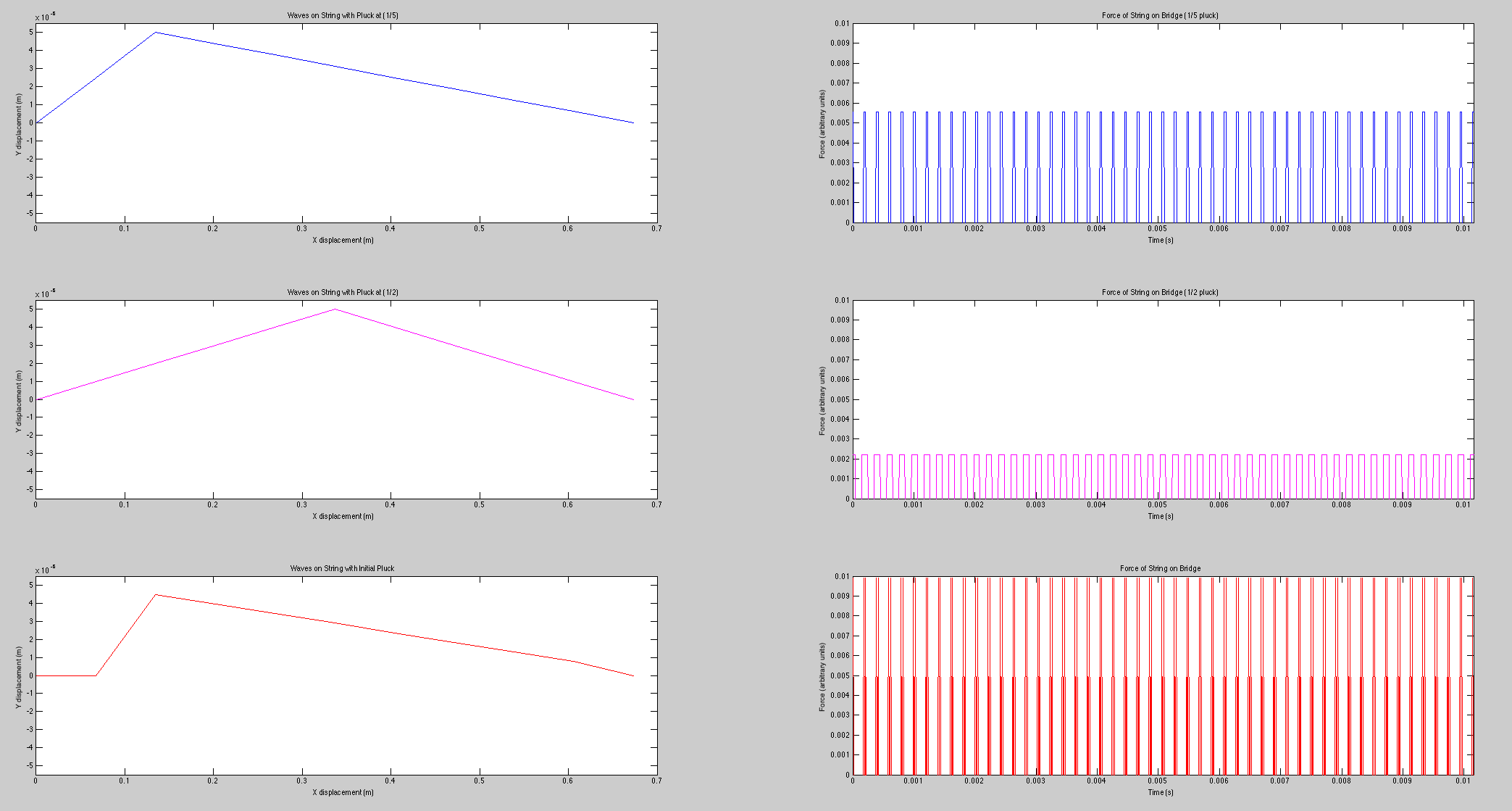
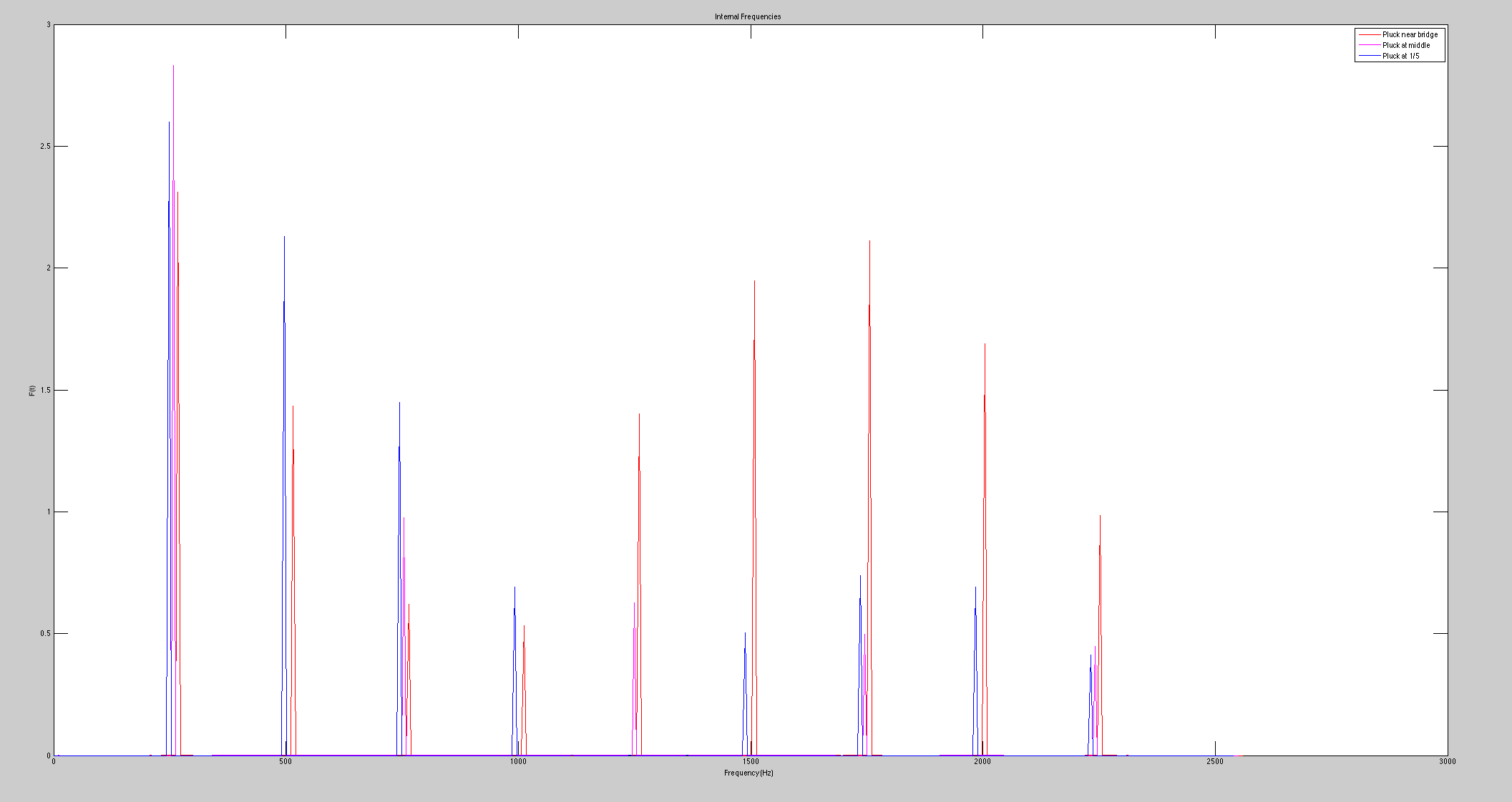
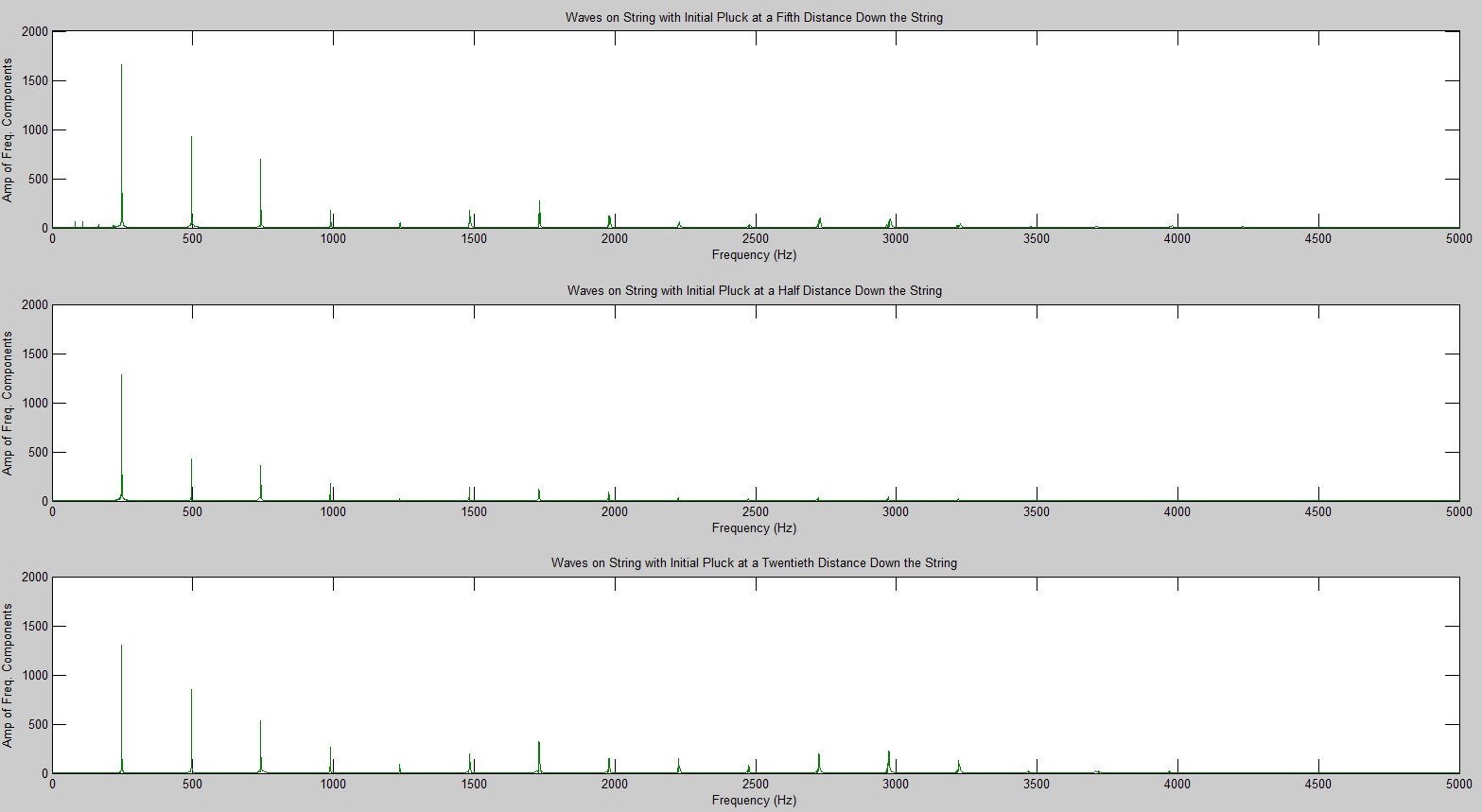
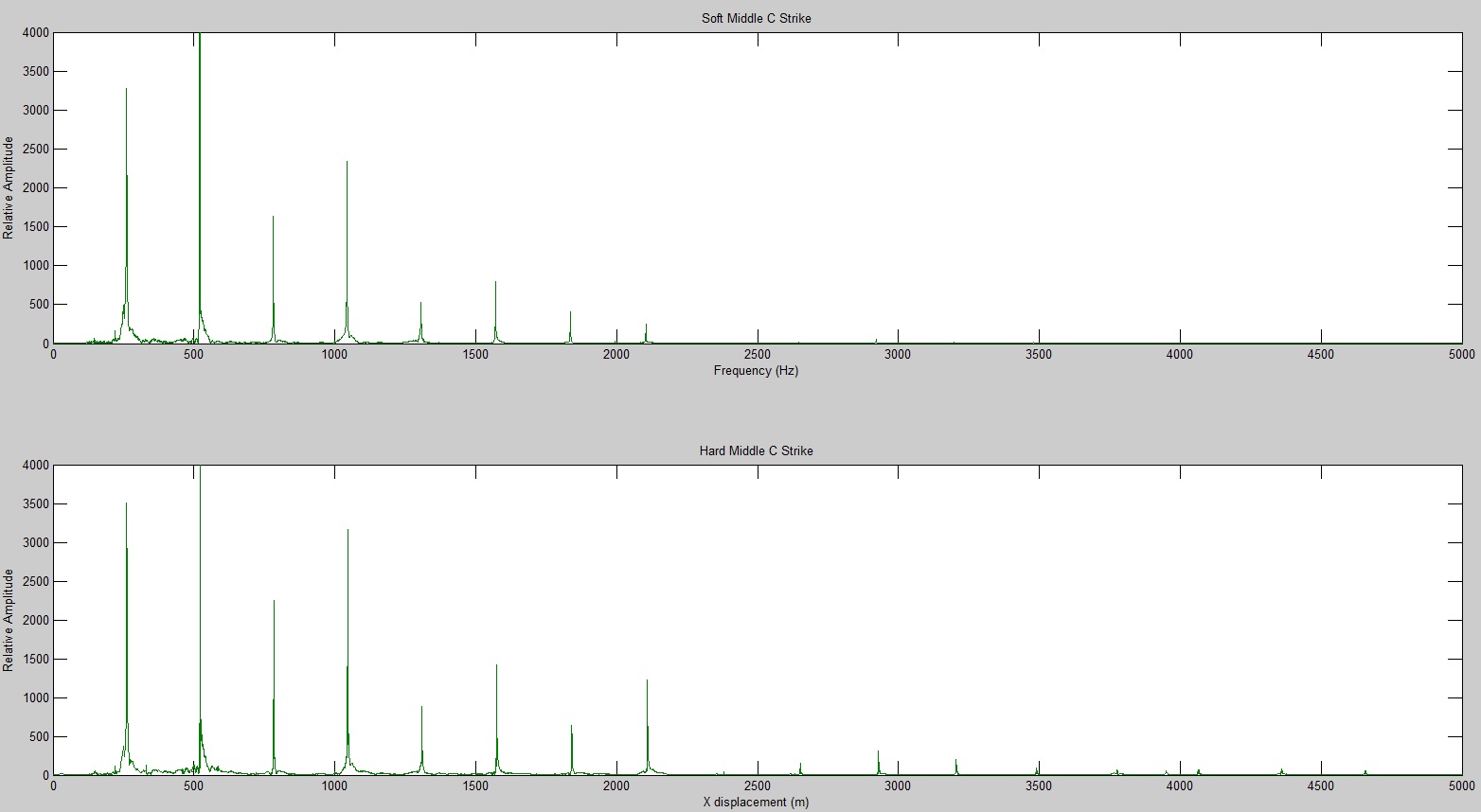
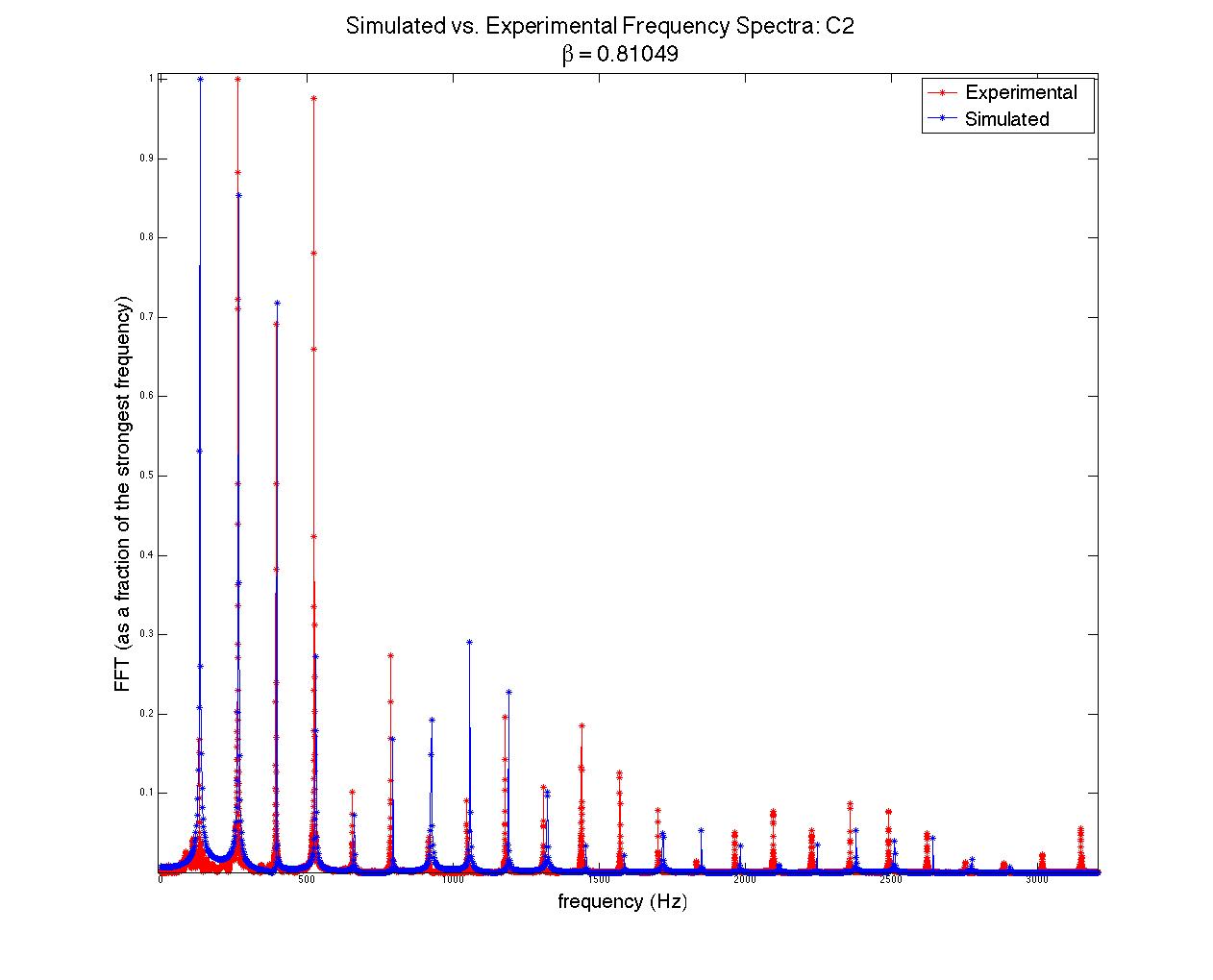
The computational model for the harpsichord was identical to that of a guitar; both are plucked string instruments that function in essentially the same way. Therefore, the initial wavefront was triangular. The plucking ratio β, a parameter used to set up the wavefront, proved to have the most effect on the frequencies generated (see figure 1). This can be explained by the formation of an antinode at the plucking point; if the string is plucked near its very edge, high frequencies will be present in the signal, as these frequencies result from standing waves on the string with much smaller wavelengths than the fundamental frequency. Because c is constant, these waves will have a high frequency contribution to the overall sound (recall that  ). Interestingly, the formation of an antinode at the plucking point prohibits frequencies that require a node at that point; for instance, a string plucked in the middle (β = 0.5) will only contain the fundamental frequency, the third harmonic, the fifth harmonic, etc., as seen in figure 1.
). Interestingly, the formation of an antinode at the plucking point prohibits frequencies that require a node at that point; for instance, a string plucked in the middle (β = 0.5) will only contain the fundamental frequency, the third harmonic, the fifth harmonic, etc., as seen in figure 1.
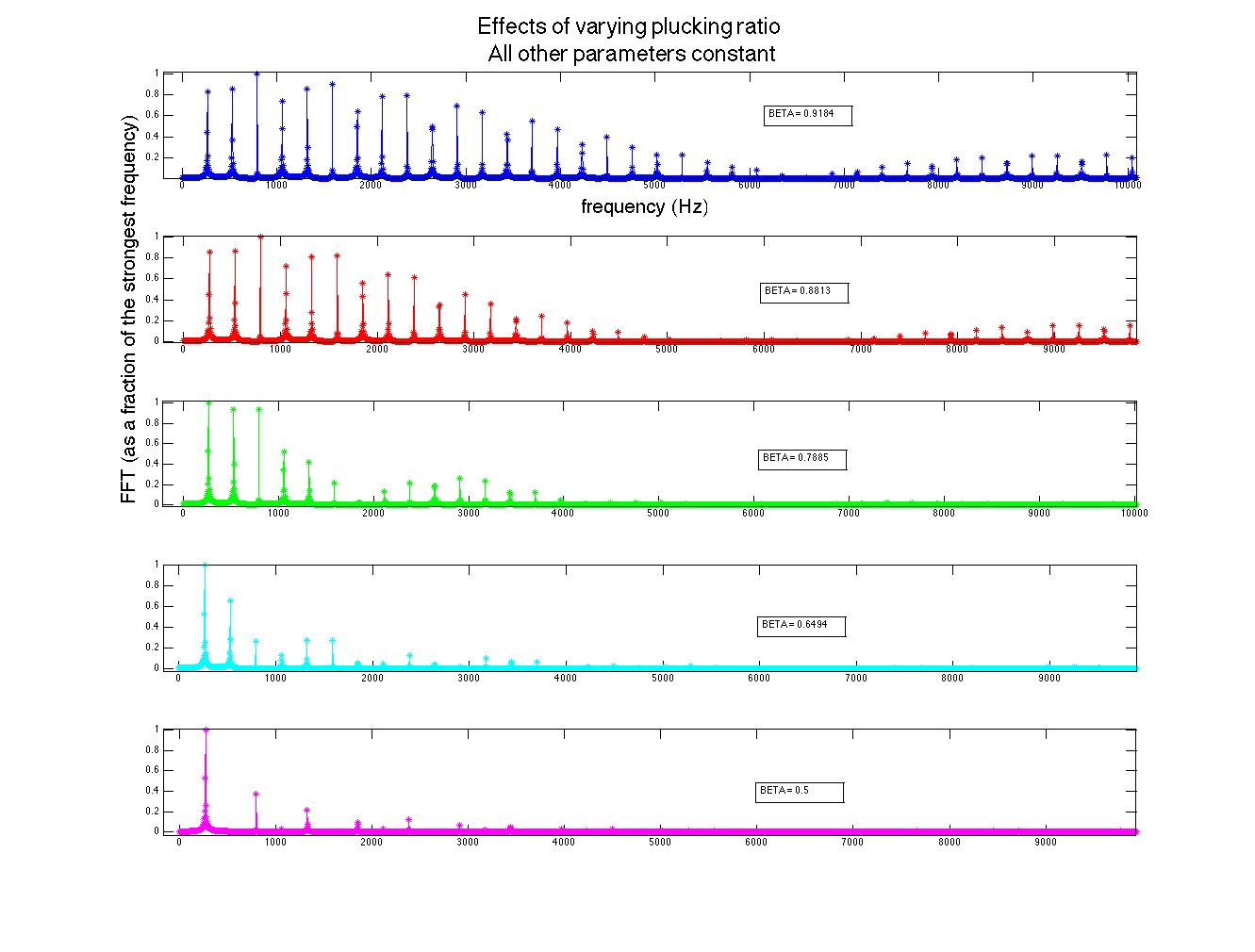
Figure 1 (click to expand): Variations in acoustic spectrum due to different plucking ratios. The strings here had a fundamental frequency of 261.63 Hz (middle c). Note that β > 0.5 simply means that the plucking point was not on the same half of the string as the bridge (sound transmission point). For instance, a plucking ratio of 0.75 is the same as one of 0.25 due to the symmetry of the string and has no bearing on the acoustic spectrum.
Changing other parameters (R, L, and plucking amplitude) had no effect on the relative strengths of the frequencies in the spectrum, assuming that all other independent variables were held constant. This may indicate a weakness in the model, as builders avoid deviating from tried-and-true ratios to avoid producing unpleasant sounds (as well as to avoid combinations of R and L that would require tensions that break strings).
The importance of β in producing a particular acoustic spectrum is evident in instrument construction. Harpsichords often have two plucking distances per note from which the player can choose, depending on the desired tonal effect.
After I developed a computational model, I compared results to recordings of individual notes from a real harpsichord. The .wav files used were part of a freely available sound bank of an instrument, designed to be used without intent for profit in musical instrument emulation software (Bricet & Garet 2007). Thus, the quality of the samples is high. Figure 2 compares the sound of the real instrument with that of the model; though the latter is clearly digitally generated, the sound produced is at least qualitatively similar to the physical system it models.
https://youtu.be/cyl98PoKdi4
Figure 2: Qualitative comparison of actual data vs. model-generated data, link here (Youtube videos do not come through for all users).
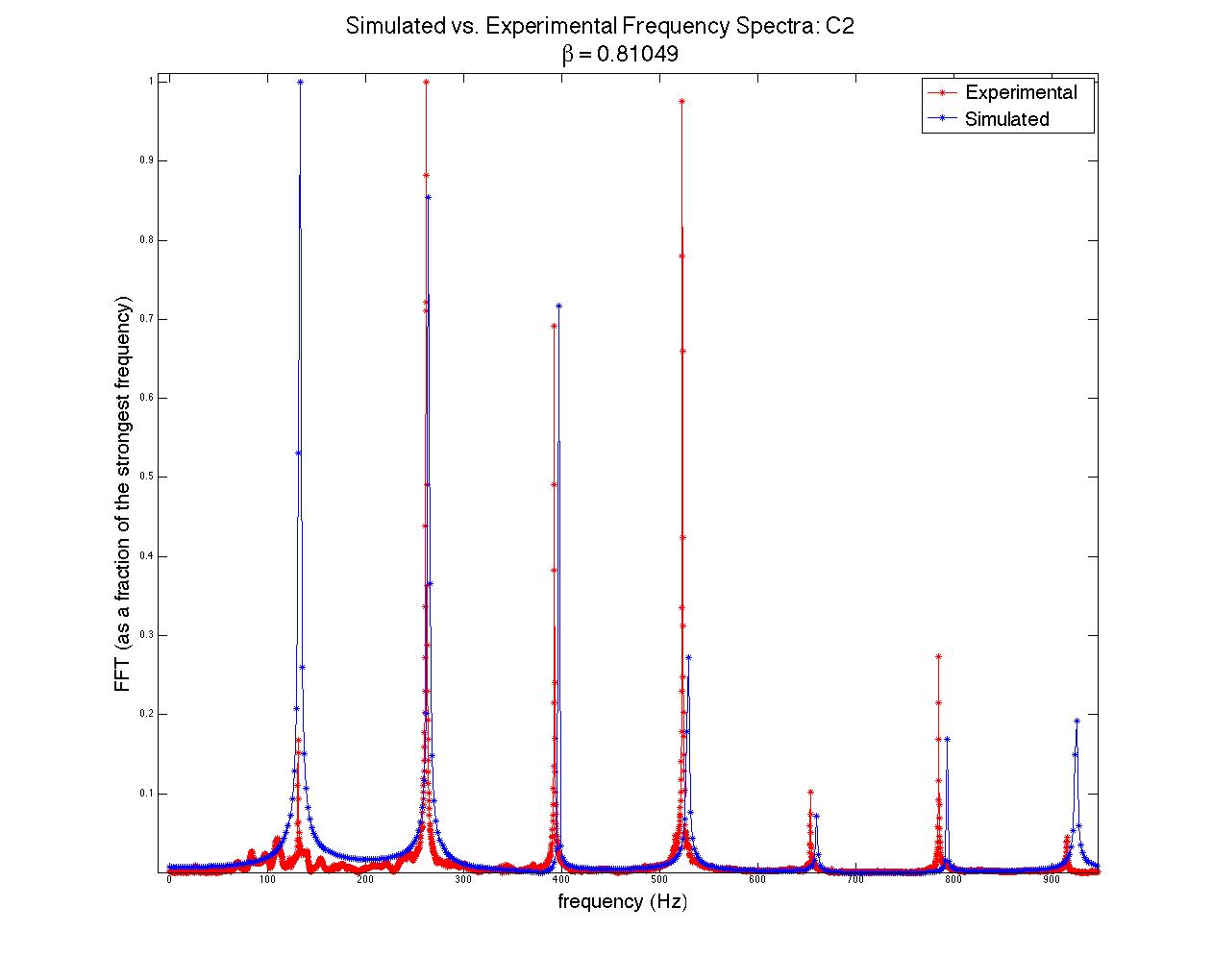
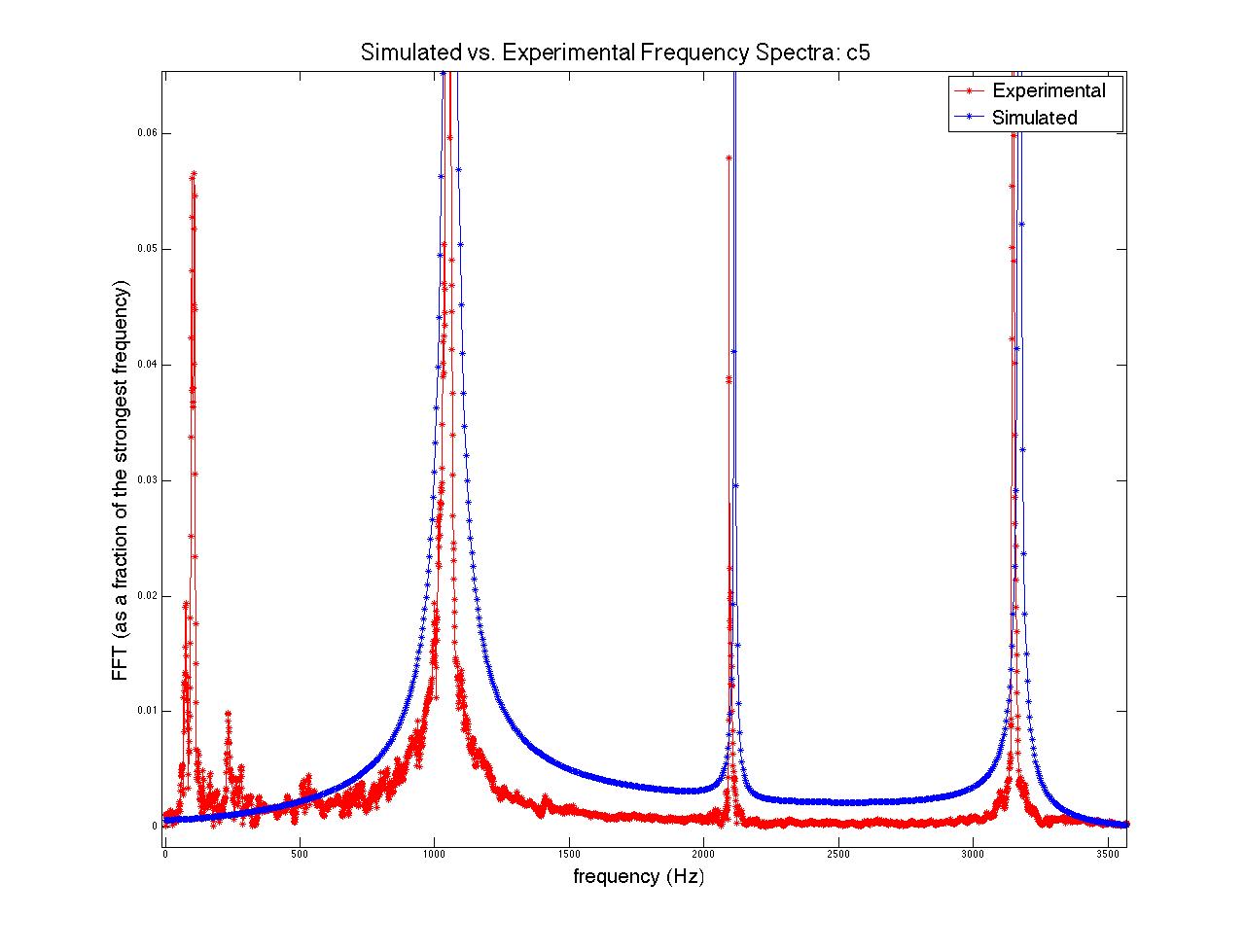
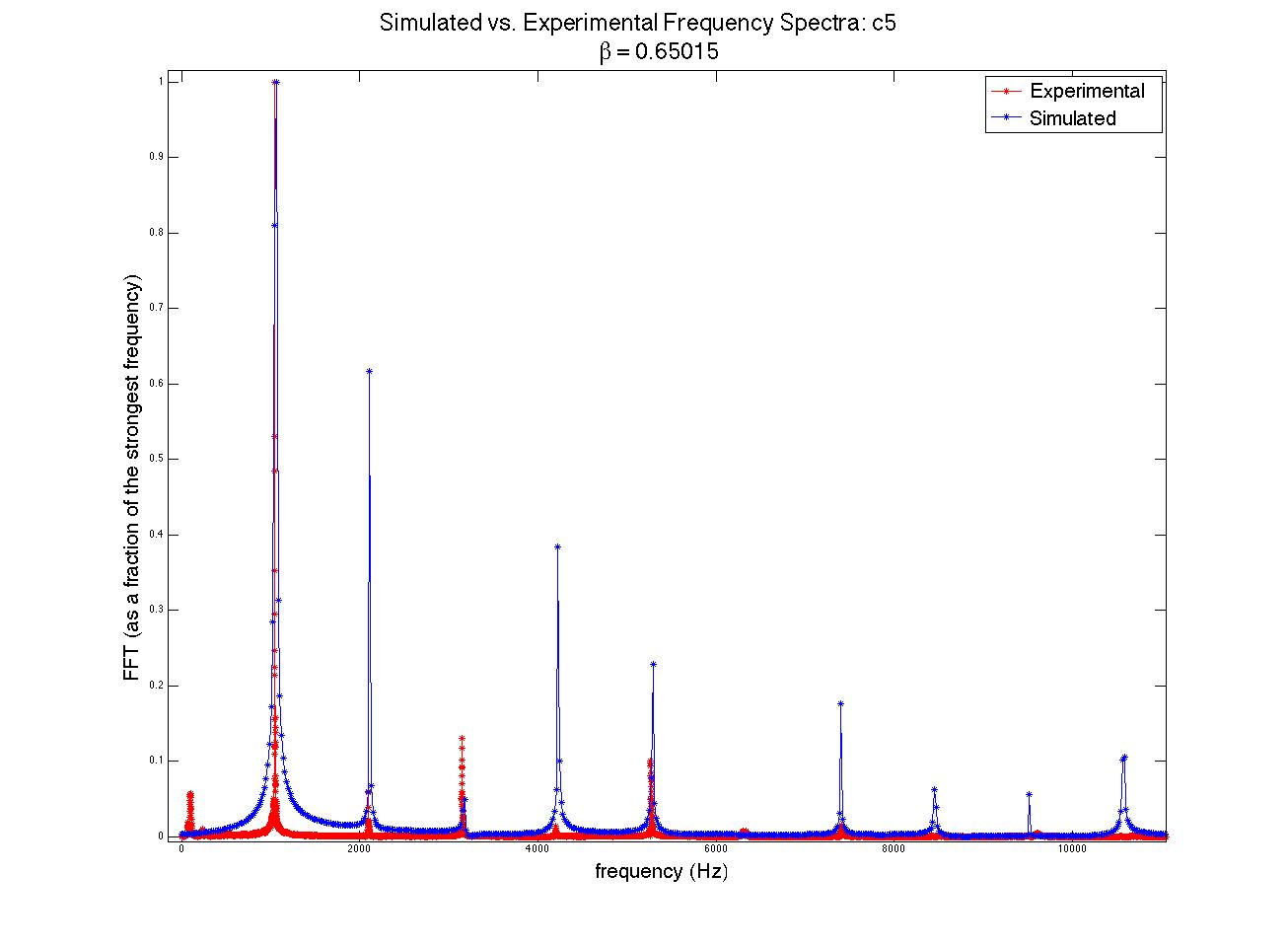
Quantitative analysis of the accuracy of the model vs. the physical data was not performed; this would have been essentially impossible without accurately knowing the plucking ratios built into the instrument that was recorded (there are no standards for β, which vary from one instrument to another and which are different note by note within the same instrument). However, I did plot generated acoustic spectra along side physical spectra in order to visually compare the model to the system (see figures 3 through 6). Though the relative strengths of the harmonic frequencies often mismatched, the model was very accurate in predicting which frequencies would be represented in a signal.
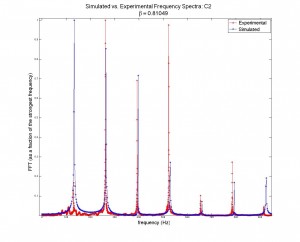
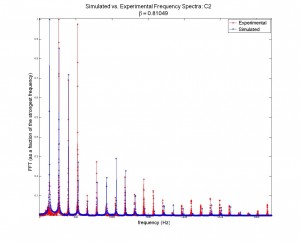
Figures 3 (at left) and (right): Model (blue) and physical data (red) acoustic spectra for the note one octave below middle c ( = 130.81 Hz). Figure 4 is simply a restriction of the data plotted in figure 3 to lower frequencies only. Some frequencies’ relative strengths matched well (e.g. second and third harmonics), while others were badly mismatched (e.g. first and fourth harmonics).
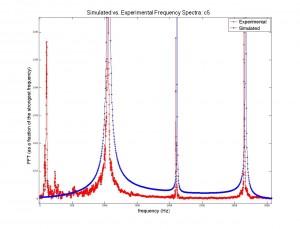
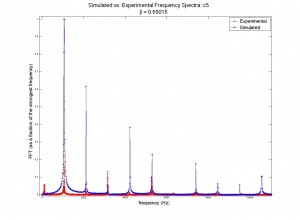
Figures 5 and 6: Similar to figures 3 and 4, but for the note two octaves above middle c ( = 1046.5 Hz).
Clavichord
The mechanism of the clavichord is unique among musical instruments. Instead of hammering, plucking, or bowing a string, the string is struck at one end by a blunt metal point (via a piano-like key). The metal point, called a “tangent,” serves as one end of the sounding portion of the string; in effect, the player directly controls the boundary conditions of the system and can even slightly adjust the tension at will. Because there is no plucking point, a new computational model needed to be implemented.
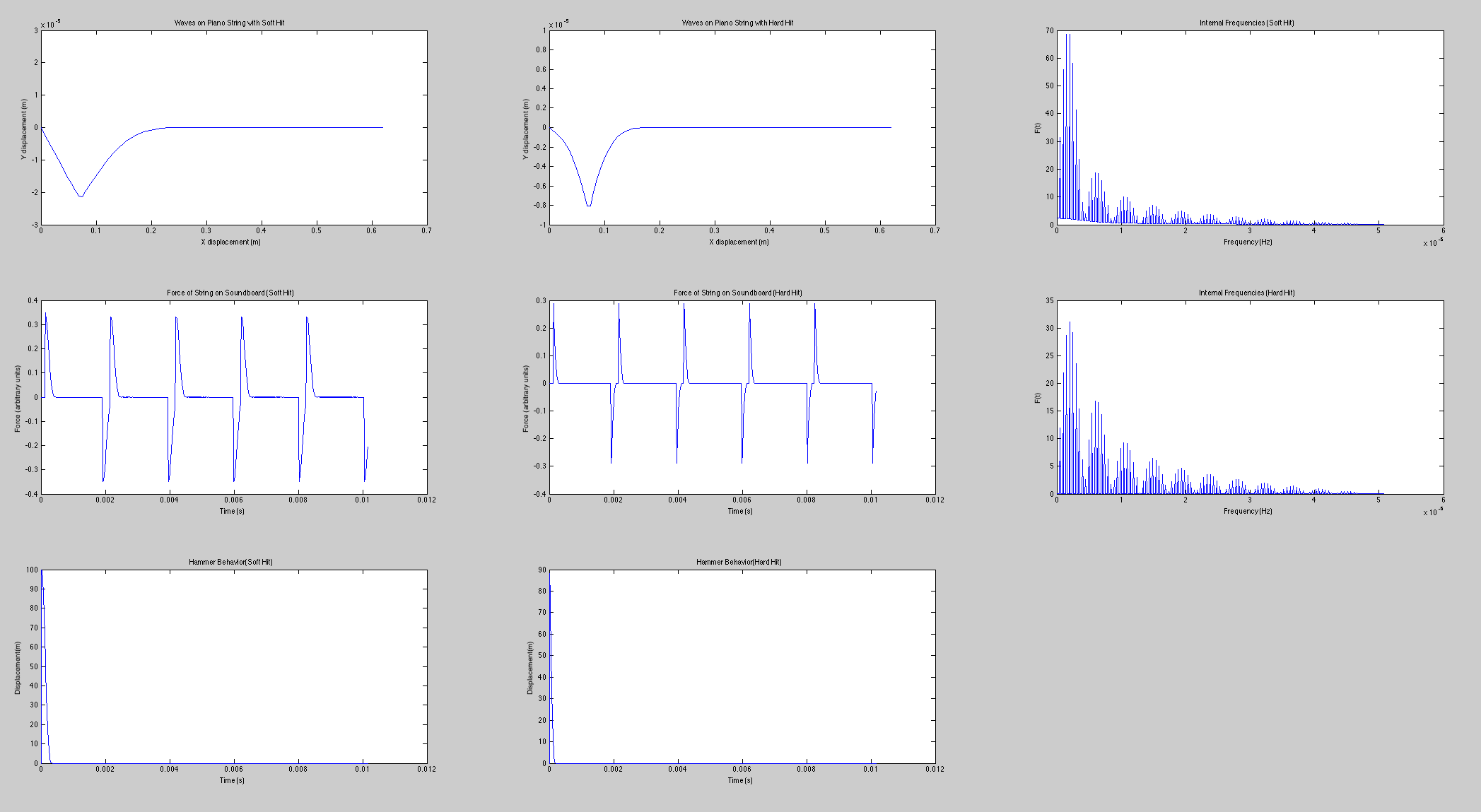
The difference between the clavichord and harpsichord required only a few changes in code. Instead of beginning the string as a triangle with a peak at the plucking point, the string began straight but with a negative slope. Upon running the program, one end of the string was raised over a length of time  ; when this time had passed, the moving end of the string became stationary, held in place for the remainder of the simulation. The time evolution of the string, the force on the bridge, and the Fourier transform (acoustic spectrum) of a note on the clavichord can be seen in figure 7.
; when this time had passed, the moving end of the string became stationary, held in place for the remainder of the simulation. The time evolution of the string, the force on the bridge, and the Fourier transform (acoustic spectrum) of a note on the clavichord can be seen in figure 7.
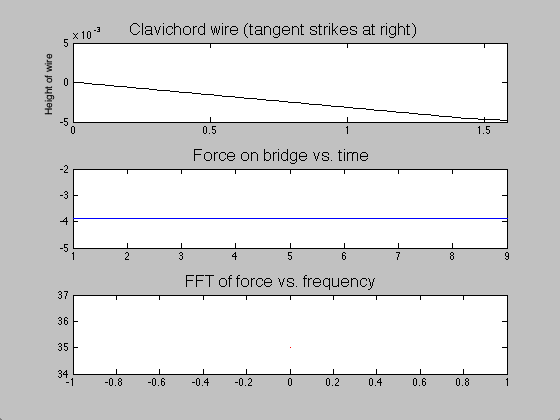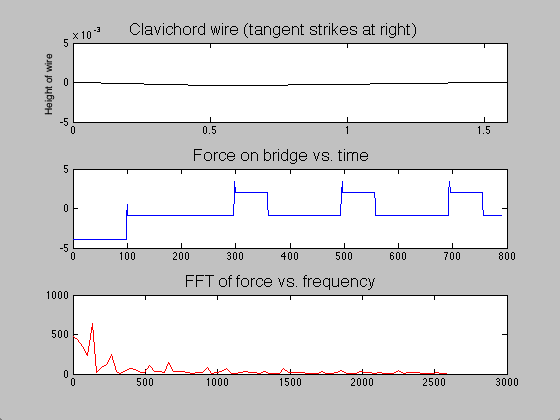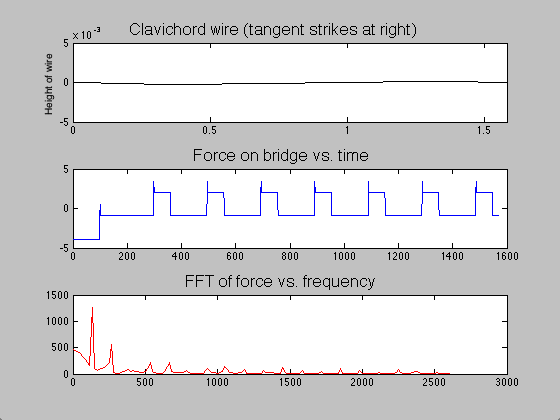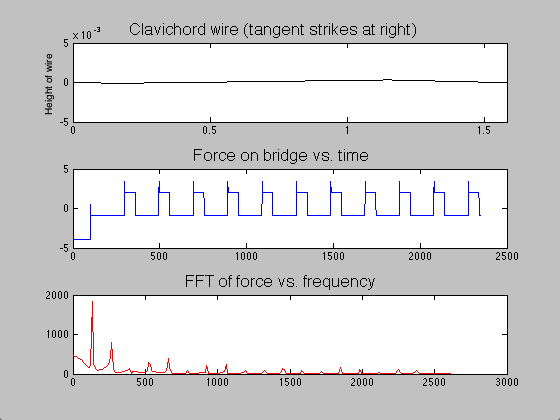
Figure 7: Time evolution of clavichord string, bridge force, and acoustic spectrum.
Though acoustic spectra could be produced as they were for the harpsichord, these would not be illuminating, as I do not have audio recordings of individual clavichord notes with which to compare. However, due to the unrealistic sound that the model generates (not provided here), I suspect that the model, which is likely a good start, may be inadequate for several reasons. The fact that the model string starts stationary on the bridge end (see figure 7) requires many time steps to “even out.” Thus, low frequencies which are not part of the actual sound may be over-represented (note the initially strong contributions by f = 0 Hz). Second, all real clavichords have two strings per note, which may interact in subtle but significant ways that this simple model does not address. Finally, the tension in a real clavichord string changes slightly as the key is depressed, and that is not accounted for in this model.
Conclusions
Though there are issues with the models, especially the one I designed for the clavichord, all were successfully implemented and, with further refinements and more accurate input parameters (which are not possible without access to the instrument recorded), these models could be applied to instrument design. For instance, one could determine the optimal dimensions to achieve a desired tonal quality from an instrument.
In summary, I tested the validity of a given model against actual data, varied input parameters to determine effects on the model’s output, and derived a new model to describe a system that, at this early stage, seems to be reasonable if not somewhat simplistic. Beyond describing Baroque keyboard instruments, which I personally found to be an interesting topic, this project was a general exercise in research on a small scale. I started with a model or derived my own, implemented the model computationally, generated computational data, and compared the results to experimental data.
Code
https://www.dropbox.com/sh/paquzk0tml03k0j/AACz5zNErUctcIUKiJtFUesJa?dl=0
Ignore requests to sign up for a free Dropbox account; files can be downloaded without one.
Bibliography
Beebe, “Technical Library, Stringing III: Stringing Schedules“. Accessed 4/21/2015 at http://www.hpschd.nu/index.html?nav/nav-4.html&t/welcome.html&http://www.hpschd.nu/tech/str/sched.html (see “Hemsch Double”)
Bricet & Garet 2007, “Small Italian Harpsichord.” Accessed 5/11/15 at http://duphly.free.fr/en/italien.html
Claudio Di Veroli, “Taskin Harpsichord Scalings and Stringings Revisited“. Accessed 4/21/2015 at http://harps.braybaroque.ie/Taskin_stringing2.htm
Giordano N J, Nakanishi H. “Computational Physics, 2nd Edition.” 2005. Addison-Wesley. ISBN-10: 0131469908.
Malcolm Rose, “Wires for harpsichords, clavichords and fortepianos“. Accessed 4/20/2015 at http://www.malcolm-rose.com/Strings/strings.html
– MATLAB R2014b by MathWorks®
“Metals and Alloys – Densities“. The Engineering Toolbox. Accessed 4/20/2015 at http://www.engineeringtoolbox.com/metal-alloys-densities-d_50.html
“Vibrating String“. Georgia State University, Accessed 4/21/2015 at http://hyperphysics.phy-astr.gsu.edu/hbase/waves/string.html




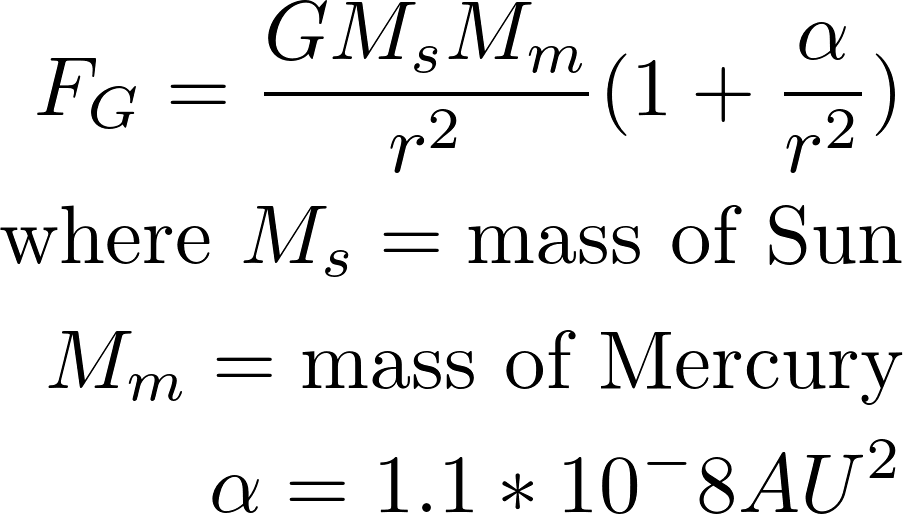
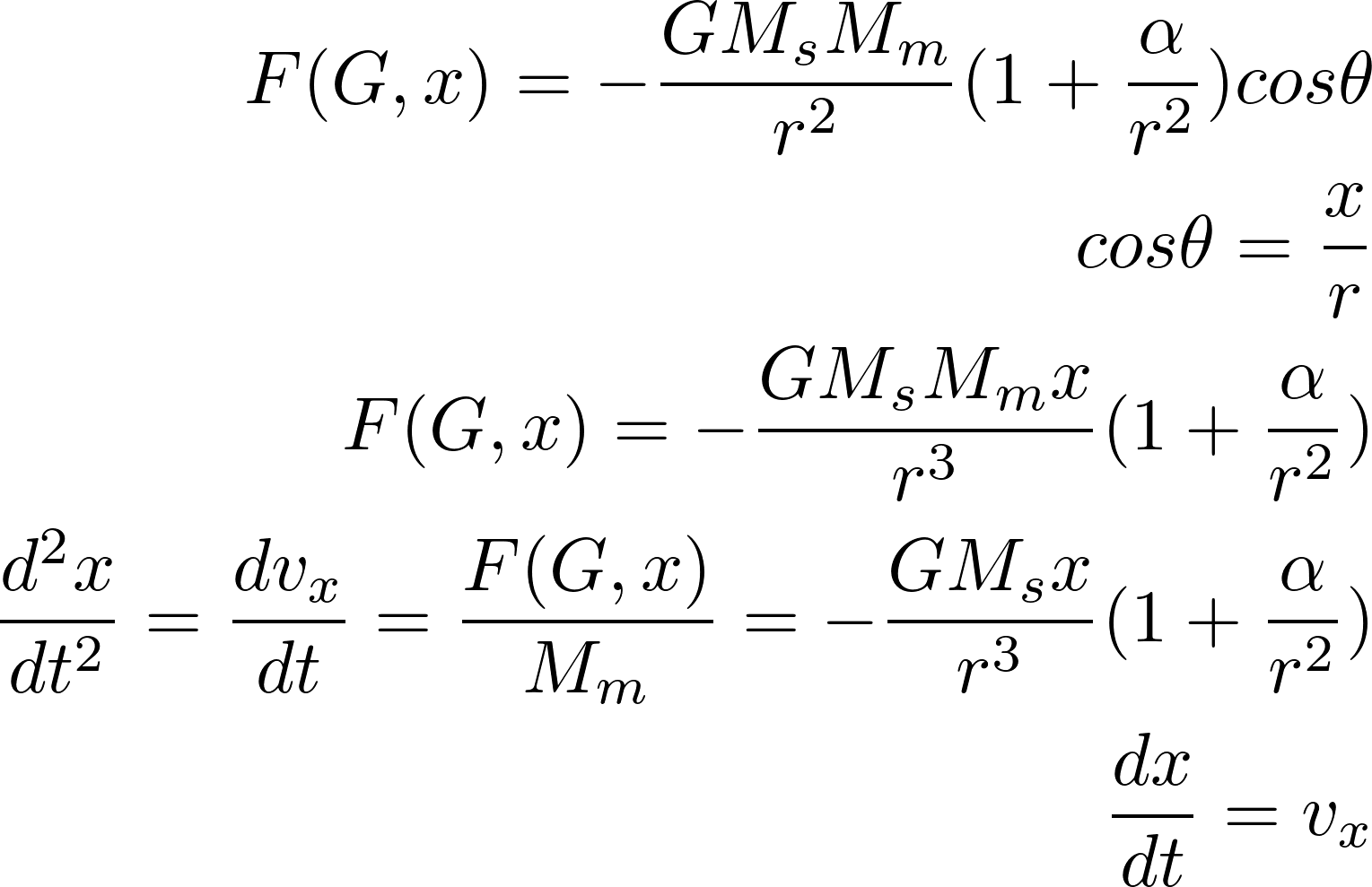
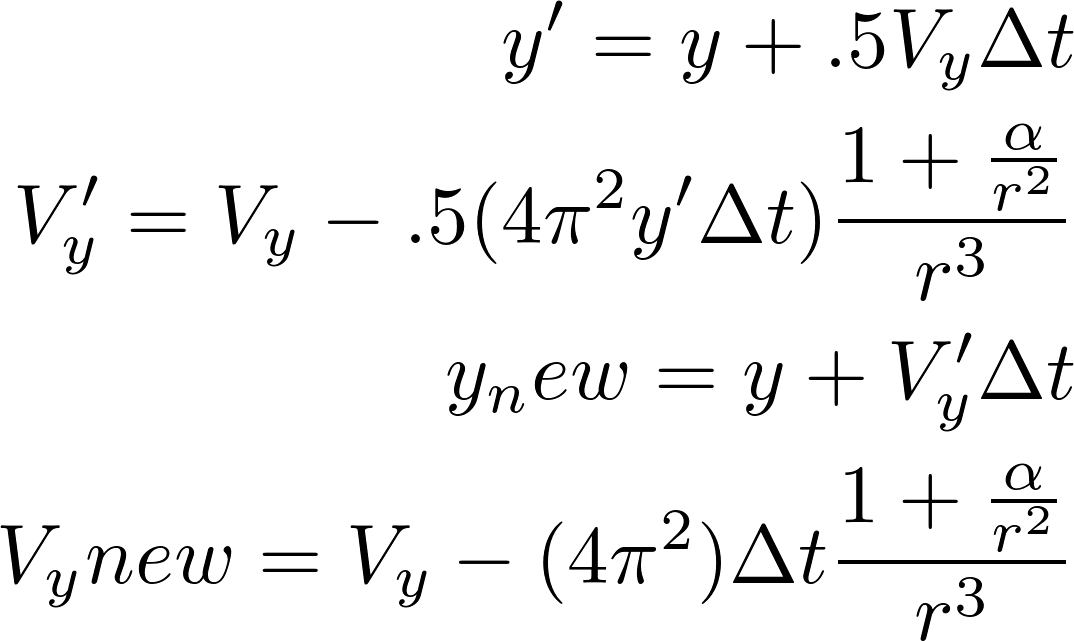
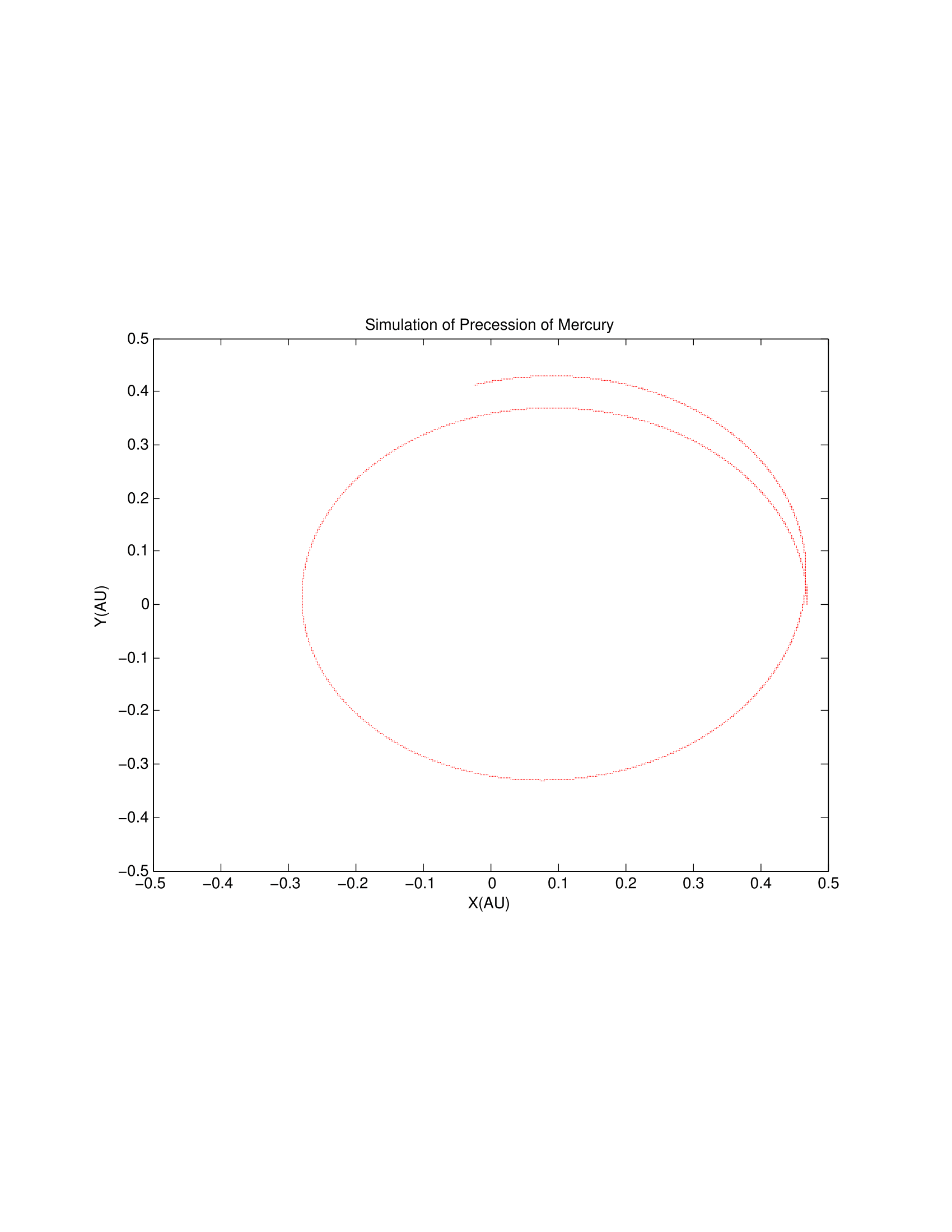
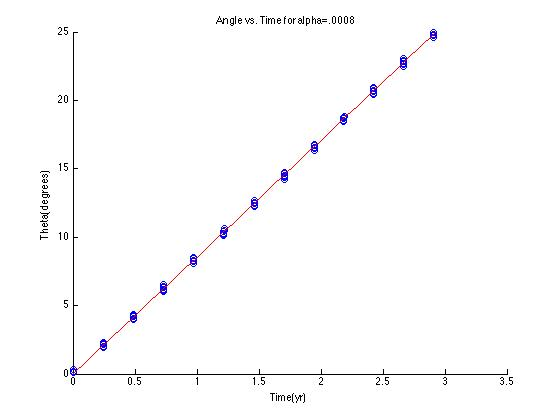
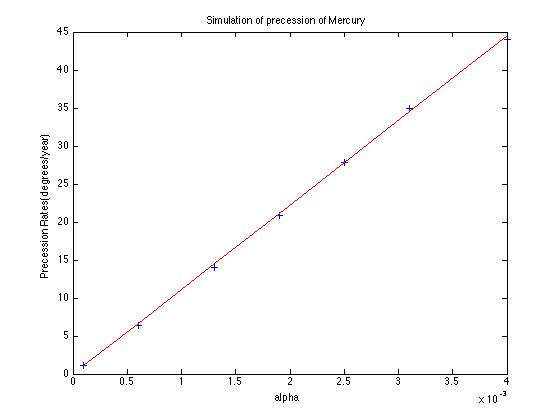
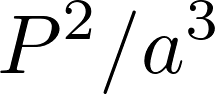
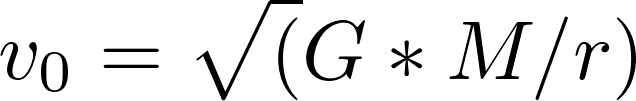
 and precession rate vs.
and precession rate vs.  . I achieved a value of
. I achieved a value of  , with a percent error deviation of 10.39 from the true value,
, with a percent error deviation of 10.39 from the true value,  .
.  . The values of
. The values of