Professor Ge and I are Interested in the impact of labor unions on merging firms’ product quality and prices. For the summer project, we devoted our attention to related theories and literature. Theoretically, both the product quality and the price effects of labor unionization on merging firms are a priori indeterminate. Consistent with the theoretical prediction, the existing empirical literature does not agree on the direction of the effects. More importantly, a significant challenge arises from the concurrent incidence of merger events and unionization episodes, a phenomenon commonly observed across various industries. Our literature review highlights two key observations: 1) There is a limited amount of research focusing on the quality impact of unionization, and 2) none of the existing literature adequately distinguishes between the effects of mergers and unionization. The goal of our study is thus to bridge these two major gaps in the literature. As part of the project, I also constructed detailed timelines visualizing the timing of the airline unionization and episodes considered in our project. In the next stage of our project, we plan to conduct a separate and comprehensive analysis of the impacts of mergers and unionization using data from the U.S. Airline Industry.
The Timelines Visualizing the Timing of the Airline Unionization and Episodes Considered in Our Project.
In the end, I hope our research can adequately distinguish between the effects of mergers and unionization. Through this way, we can not only make contributions to the limited amount of relevant research focusing on the US Airline Industry but also help the later studies related to unionization and mergers effects.
Otis Boss Receives a Lighter, 1968 (courtesy of USMC Flickr). On top of combat photographs, Sergeant Atwell took many intimate shots of soldier life often unseen by civilians. In this photograph, Major General Tompkins presents Private First Class Otis Boss a lighter after Boss saved his Battalion by catching the attention of an aerial observer with only a match.
A picture may tell a thousand words, but this summer I learned that they can also spark a million questions.
I spent eight weeks searching for and analyzing photographs for Professor Brigham’s forthcoming memoir about his biological father, Bruce Allen Atwell. During the Vietnam War, Atwell took some of the most seminal images of the conflict. For decades, Professor Brigham used these photographs in his courses without knowing his connection to their photographer.
My first task––identifying soldiers in a selection of Atwell’s photos––seemed insurmountable. With the help of Professor Brigham’s memoir and other texts about the war, I got a rough idea of what platoons and events Atwell photographed. I searched online for message boards, Facebook groups, and websites created by Vietnam veterans that Atwell potentially photographed. I was able to identify almost every unknown soldier in Atwell’s photos with the help of these veteran-historians and their commitment to documenting their Vietnam experiences. Knowing the names of the subjects allowed me to draft meaningful, informative captions to go along with the images for the memoir.
I was unable to identify the Marines in this photo, except for Robert Wallace (far left). I am indebted to Sgt. Maj. Eddie Neas for his assistance in this identification and many others. He not only shared the names of his fellow veterans, but also stories––which enriched my understanding of these photos and this conflict immensely.
I spent the second half of the project searching for more of Atwell’s photographs from his time in Vietnam, as well as his time in Cuba and as a White House photographer for the Marines. From National Archives branches to small repositories at private universities, I cast a wide net when contacting archives. I was able to track down 21 photographs taken by Atwell that Professor Brigham did not have before.
The mysteries I solved and the photos I found made all the obstacles I faced during my research worth it. Professor Brigham’s story is so compelling, and working with him pushed me to consider new methods of telling history: through powerful personal narratives and photographs.
Gioia Marchiano and Olivia Kane interviewing Jayant Kairam ’03, former director of Environment & Sustainability at Walmart.
This summer, our group – Kae Czeasak, Olivia Kane, and Gioia Marchiano – worked with Professor Seidman on the Climate Solutions and Climate Careers website. The site is divided into two sides – one that provides a comprehensive understanding of the solutions necessary to address climate change, and another that focuses on careers in climate. Over the course of the summer, we focused on building out the Careers side of the site, and fleshing out a database of climate technology startups.
We worked on pages for many different kinds of careers – Environmental law, Urban planning, Finance, Corporate Sustainability, International Development, and Culture and Communication. We researched to find inspiring resources that could inform students and young professionals about these careers. We also conducted interviews with professionals in some of these fields – environmental law, green building design & retrofitting, and corporate sustainability – to provide students a glimpse into careers they might not have much previous knowledge about. As we wrote these pages, we took care to be intentional about our audience. We sought to inspire readers and help them feel that there was a space for them in climate even if they did not come from a science background or were not interested in stereotypical technical climate change careers.
Another aspect of our project was working on a database of climate tech startups, with a focus on green startups in agriculture. This database provides site users with a broad list of companies working on exciting and under-the-radar climate solutions today.
This site is not done; work will continue to build out the careers page and database. We want the site to function as a hub that can point readers to high quality resources about climate change and climate careers. The careers side highlights careers that are not traditionally thought to be involved in climate change, such as finance. Our goal was to help every reader see that they can have a place in the climate fight.
Scholars: Soliana Kasa (’24) and Vanessa Mark (’26)
With the initial subject being the scholarship of women of color and craft, we took interest in different aspects of this broad niche.
I created an annotated bibliography focusing on quilting circles and bees, sewing, weaving and the community-building aspect of craft arts for women of color. One of the main framework questions I had thought of to guide my research was what made crafts produced by African American women different from those made by European-descended Americans. I immersed myself in the African American tradition of sewing and quilt making, dating back to the days of enslavement in the United States. They used techniques like those used in tapestries made by the Dahomey people in West Africa. I got to read articles that delved into the rich history of this tradition amongst African American women and their ingenious contributions to the craft, which are often overlooked in the historical discourse around American quiltmaking, and a sense of community interconnected with the practice of quilting.
Beginning with finding the distinction between art and craft, I found that much of the art world had roots of elitism, whereas the craft world was an outlet of creativity to women of color. Reading feminist theory provided interesting insight on crafts. Alice Walker and Audre Lord find that women of color use crafts as an expression of agency. I ultimately applied this lens to the experience of Japanese Americans during WWII internment camps, where creativity and expression proved to be a lifeline for many. This research allowed me to explore two seemingly unrelated subjects, and find the connection between them. I compiled relevant readings into an annotated bibliography. I was able to genuinely explore these subjects for the sake of learning, without the pressure of a final assessment or grade.
Project : Translating a 19th-century Feminist novel: George Sand’s Jacques (1833)
This summer, Izzy Kaufman-Sikes and I worked with Professor Hart to explore Thelma Jurgrau’s preliminary translation of George Sand’s novel Jacques. Using Jurgrau’s draft as a starting point, we explored a variety of translation tools, including the latest version of Chat GPT. We were curious to see how the recent developments in artificial intelligence might assist translators, particularly those translating an older work with a style and syntax no longer in use. Although we found the speed at which Chat GPT translates and its ability to create several different versions of a translated text to be incredibly valuable, oftentimes the best insights came from our collaborations with each other and with Jurgrau’s text.
This project required close attention to historical details such as gender relations, class and economic structure, the politics of the era, and French colonialism. Like many nineteenth century novels, Jacques centers around the souring of a mismatched marriage during a time in which divorce was illegal under the Napoleonic Code. Fernande and Jacques, the couple around whom the novel centers, are immediately shown to be ill-suited for one another: In addition to being twice Fernande’s age, Jacques is also reclusive, mercurial, and taciturn. Although Jacques resembles classic novels like Austen’s Pride and Prejudice and Persuasion—an overbearing mother, a volatile ex-soldier, a concerning age gap—Sand’s salient social critiques set the story apart. Sand not only condemns the Napoleonic Code but also discusses taboo topics like suicide and infidelity, even challenging the institution of marriage itself.
With the new surge of interest in classic literature, from book recommendations on TikTok to a shout-out to the 1995 adaptation Pride & Prejudice in the new “Barbie” movie, an English translation of Jacques cannot arrive soon enough. While Sand’s feminist ideals are cloaked in polite language and subtlety, modern readers will surely appreciate her radical thinking just as much as they did almost 200 years ago.
Professor Kimberly Williams Brown’s research focuses on Afro-Caribbean women teachers who have come to the United States for various reasons: greater access to resources, professional development, and economic advancement, to name a few. These women teach in different school districts primarily in New York, North Carolina, and South Carolina. PWB has collected interview & survey data in 2016, 2021, and 2022 and works to pull out emerging themes across these different conversations and submissions. Some of these themes will be explored further in future papers and a book.
Together we are using MAXQDA to code transcripts from the teachers’ interviews and organize the data by theme. Some of these themes include: racial identity, effects on children and family, pedagogical style adjustments, and the documentation process. We are also developing a paper proposal for the American Educational Research Association (AERA) centered on the dissonance between the way administrators regard these teachers and the depth of care the teachers demonstrate for the craft of teaching and commitment to their students.
I took two classes with Professor Williams Brown during my first years at Vassar and am deeply interested in her research, critical pedagogy, and the authentic way she connects with students. While initially drawn to the Ford Scholars program because of PWB, the more I learn about her research, the more I realize how the experiences of transnational educators speak to far more than what takes place in a classroom. These Afro-Caribbean women discuss the complexities of the documentation process, the harrowing loneliness of leaving communities behind, and the pressure to make the most of an opportunity despite the challenges making life away from home difficult. I am grateful to read these narratives and gain a deeper understanding of race, gender, the U.S. educational system, and Afro-Caribbean teachers.
An unaccompanied migrant is a child who arrives at one of the United States’ borders without an adult with them. Typically, they arrive at the southern border. Their status stays with them even after they are united with a sponsor.
We rightfully hear a lot about the difficult realties they encounter attempting to journey to the United States as well as once they arrive. But while these situations are more than worthy of our attention and advocacy, it is only the beginning of an extremely challenging chapter for these children.
After reunification with their sponsor, their new life in the United States begins, at least for the time being. Immediately, appearing in court becomes their number one priority. Whether the child has been reunified with a distant relative, a family member that acts in a parental role, or a biological parent, their goal is to assure their life in the United States. Needless to say, this is a difficult process.
To learn more about it, Prof. Holland and I watched New York City immigration court on numerous occasions, in-person and on Webex. We learned that because of long waitlists at pro-bono organizations and steep prices from immigration lawyers, defendants would frequently appear without representation and had to request continuances from the judges. We also learned that these continuances are limited, and that at some point, these cases must continue, with our without representation. Such a distinction, the numbers show, can all but decide an unaccompanied minor’s case.
This caused us to focus even more on our original question: what role do schools play in all this? By interviewing a former judge, attorneys, employees of pro-bono organizations, and an english language teacher, we learned that this was a worthwhile question, one that we should continue to ask.
Unaccompanied children are an extremely vulnerable demographic, making the support system that school can provide important. At school, they can learn English and about the legal process they are a part of, and they can find support in their teachers and school guidance counselor. Through school, they can interact with their judge in a non-confrontational manner by presenting a certificate of accomplishment at school—they can become more confident. Through school, kids can receive assistance from social workers in finding legal representation. And in some judges’ courts, proof of enrollment in school excuses them from needing to appear in court at all, as long as they have a sponsor or attorney to represent them.
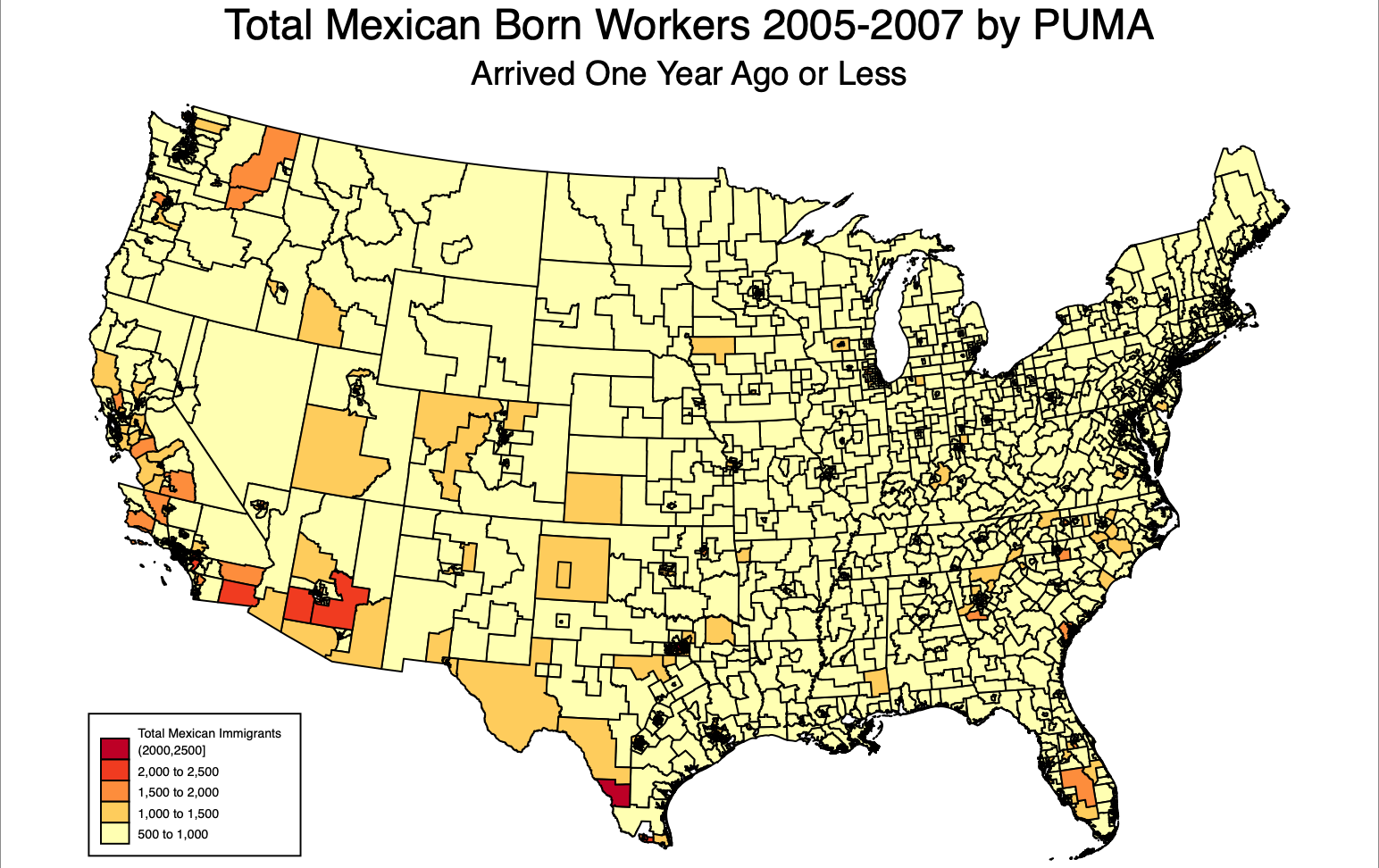
Using the American Community (ACS) to study declining Mexican migration over the past eight weeks has allowed me to gain a better understanding of the industries and locations across the United States that were most impacted by the change in migration patterns from Mexico following the 2008 financial crisis.
Beginning with a literature review, I learned about the known patterns of Mexican-born workers, and what factors affect their decisions to move to and within the United States. Economic literature analyzing migration patterns from Mexico has drawn attention to the tendency for immigrants to move to areas in which migrant communities already exist. Knowing a network of workers allows immigrants to learn about job opportunities and lowers the costs of migration through information sharing.
Creating maps using data I observe changes in the population density of new Mexican immigrants across the Sun-Belt and Midwest regions.
I then used data from the Mexican Migration project to track the prevalence of migrants within the average migrant community in each state. The prevalence ratio provided an indication of migrant community depth that I could use to run a regression exploring the driving factors behind the variation in migration patterns across states in response to the great recession.
Over-all this summer has provided an insight as to how to use large surveys such as the American Communities Survey and Mexican Migration Project to draw conclusions on how specific populations respond to changes in the economy. I enjoyed working with maps, data, and literature to explore these questions and discover ways to identify trends within data and explain specific behaviors among a specific population.
As the Ford Scholar for the project “The Political History of Classicism,” under the guidance of Professor Dozier, I researched interpretations of and reactions to the Classics, predominantly by hateful groups. It’s challenging to outline one specific task or goal that’s been the central focus of these few weeks because discriminatory interpretations of antiquity are numerous and seemingly never-ending, so my tasks have been almost Sisyphean. The duties that are easiest to describe are proofreading and editing articles and bibliographic checking. Most of my time, however, was spent researching and reading sources: modern, ancient, and everything in between.
‘Classical’ antiquity has been used for centuries in conjunction with elitism and exclusionary institutions and as a result, the source material for this project dates from the first century CE, up to the present day. On the ancient end are writers and orators like Strabo, who perpetuated distinctions between Greeks and non-Greeks (barbarians, as he calls them), and Libanius, whom Montesquieu cites for evidence that Athenians put to death foreigners who attempted to vote. On the modern end, sources range fromthe Founding Fathers to Know Your Meme, a website with innumerable memes—many of them hateful with some using antiquity to justify that hate.
In the earlier history of the United States, ancient sources were used to justify slavery as well as imperialist expansion. Rome, an empire that had subdued, assimilated, and committed genocide against various nations and peoples, was considered a guide for expansion by American politicians. As such, Rome was an eerily fitting example for Manifest Destiny, an undertaking that resulted in the displacement (if not slaughter) of innumerable Indigenous Americans. Greco-Roman antiquity was a useful ideological tool, considering that many early Americans were raised reading Greek and Latin texts, with references to antiquity in their English materials as well.
Up to the modern day, Classical education has undeniable associations with conservatism and hateful politics. Part of my work was looking into these connections, with one Classical school in Flordia providing the location for the signing of Ron DeSantis’ “Don’t Say Gay” bill. Further associating Greco-Roman antiquity with his homophobic agenda, in a recent video, DeSantis’ team touted his transphobic policies inter-spliced with masculine symbols, one of which being Brad Pitt’s Achilles. Evidently, DeSantis has not only an interest in hateful politics but in history as well, with some notable exceptions for certain historical topics.
Title of an essay Prof. Dozier and I composed on the subject of DeSantis’ campaign ad for Pharos: Doing Justice to the Classics this summer
The Classics’ classist (and racist, and homophobic, and sexist…) roots continue to express themselves into the modern day, with prominent hateful figures using Greco-Roman antiquity to attack—or justify their attacks on—minority groups. This is a non-comprehensive sampling of some of the work I’ve been doing throughout the summer.
Personally, this project has provided me with skills and knowledge that I easily see influencing future thesis and graduate research. My greatest takeaway has been how information, facts, and knowledge are never apolitical, despite the desire of many to make it so. Whether that information is in the form of a meme or an ancient text, the compiler always inherently and often unintentionally carries along their own biases. Even the lack of knowledge is political, as Dan-El Padilla Peralta outlines in his work—which has stayed with me long since reading it as one of my first tasks—about epistemicide, or the destruction of knowledge systems. The Library of Alexandria is mourned by historians and non-historians alike (despite its demise being caused by largely bureaucratic and political forces), but what about the information that’s been destroyed because of Greco-Roman antiquity? Consider how much indigenous knowledge and ecology has been lost or deliberately extinguished, from that of the Gauls in ancient Europe to the First Nations of the Americas, because of the genocidal actions of the Roman Empire. In this light, the goal of this study has been to illuminate the ways knowledge of and from antiquity has been and continues to be used for oppressive purposes and to make others aware of these hateful influences.
This summer, I worked with Hadley Sparks on Professor Kathleen Hart’s Ford project focused on translating a 19th-century epistolary novel: George Sand’s Jacques (1833). Like other 19th-century feminist novels, Jacques criticizes the impossibility of divorce under the Napoleonic Code, highlighting a couple’s incompatibility as the basis for their unsuccessful partnership. The inspiration for this project was a preliminary translation of Jacques, produced by the late George Sand scholar Thelma Jurgrau, which provided a set of questions to consider and an initial foundation from which our translations could develop.
Over the course of the project, we became well acquainted with key principles of translation. We spoke of the importance of maintaining equivalence between the two texts, finding a balance between precise vocabulary and capturing the sentiment and flow of the original sentences. Translation, we also discovered, should not be a solitary process but rather a collaborative one. Examining what in Hadley’s translation was similar to or different from my own—discussing our impressions of the book, methods of translation, and reasoning behind choices—greatly elevated the quality of our work.
We employed a myriad of online resources to help us in our translation process, using WordReference for individual words and Google Translate and Linguée to produce rough translations of the text for necessary alteration. Additionally, we utilized the latest version of ChatGPT to gauge how AI might be able to supplement (though never replace) the work of a translator. We found ChatGPT to be helpful in its speed and ability to produce different versions of a passage, but very limited in its capacity to make translation decisions requiring cultural knowledge and to capture tone or voice.
Throughout her novel, Sand condemns the marriage laws of her time—in particular how they disadvantage women—yet she does not write in an overtly confrontational manner. Indeed, Sand believed that efforts to change society abruptly would hinder the advancement of women, and thus she often distanced herself from feminist causes. Nonetheless, her novel has a feminist subtext and many radical elements. Translating Sand’s Jacques intoEnglishoffered me eye-opening insights into a subtle form of feminism—and, hopefully, the translation itself will illuminate for a wider audience how a female novelist sought to use narrative to criticize unjust laws and challenge prevailing gender relations in 19th-century France.