
This summer under the Ford Scholars program, I worked with Professor Dustin Frye and Andy Kasper ’23 to create a semi-automated approach to historic data collection. The site for the development of this approach was the County Business Patterns dataset, a record of business statistics in each county by industry. Prior to the later 20th century, this dataset was produced without the use of electronic recordkeeping, and these earlier versions of CBP exist only as physical copies and image-only scans.
For this project, we sought to turn these image-only scans into workable datasets, with the end goal of analyzing long-term changes in and consolidation of job availability by county. Because Optical Character Recognition software is prone to errors, we decided on a double-entry system, where outputs from both Google’s Tesseract and ABBYY’s FineReader could be combined, cross-referenced, and eventually consolidated into a singular output.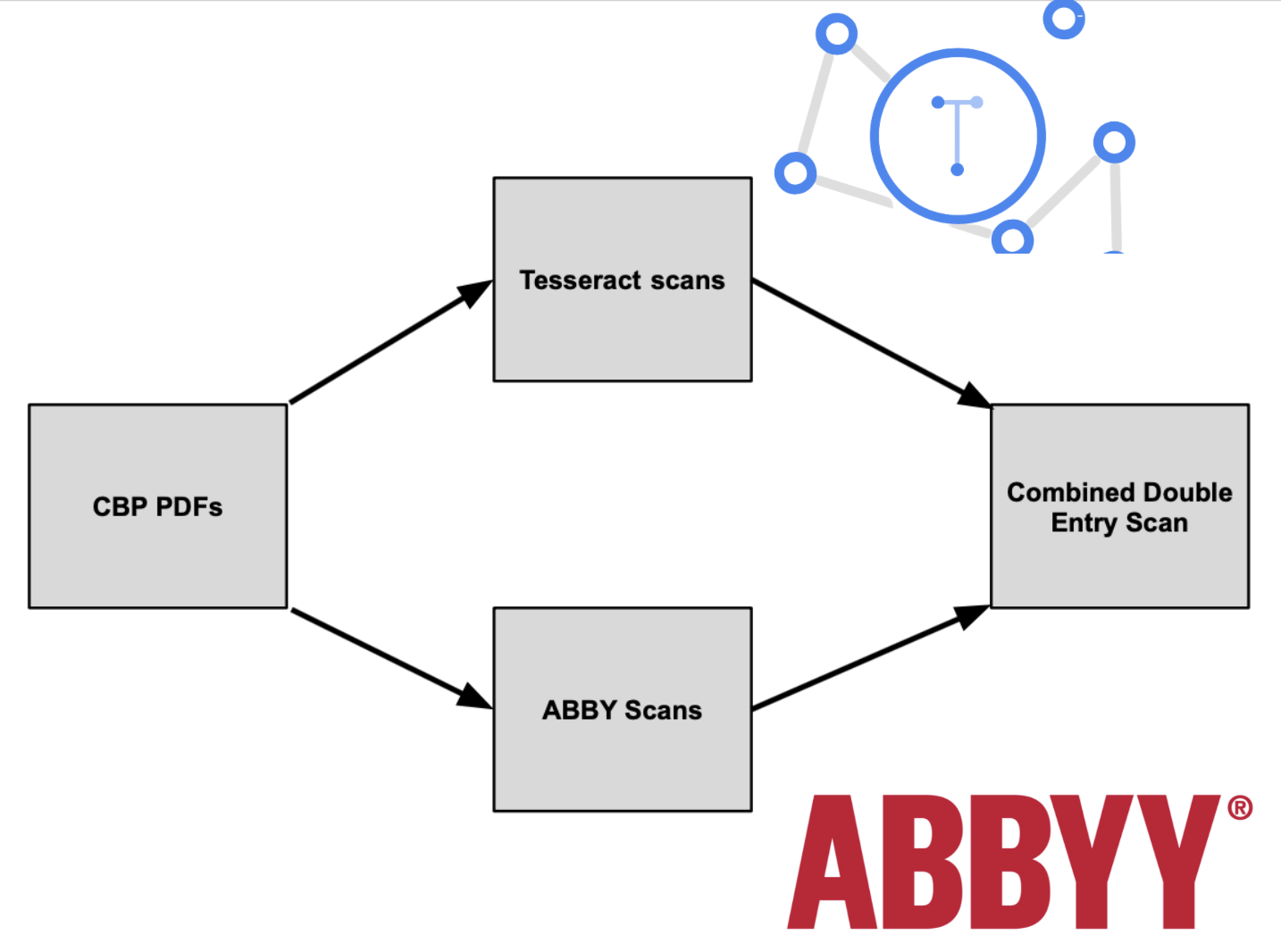
While Tesseract is freely available, it lacks ABBYY’s built-in ability to replicate tables; my work this summer focused on creating this functionality from the returned list of words and their positions on the page. Based on the results from this summer and given the greatly varying quality in the scans we used, I have a high level of confidence that this code could be expanded and generalized to be able to extract data from a wide variety of sources. While both OCR programs routinely make errors, they tend to make different, predictable errors (for example, “5,039” may be read as “S.039” or as “59039”, depending on which is used), and the reconciliation process to join the outputs from these two is able to take into account the errors each program is likely to make to produce a single dataset with much greater confidence than that from either of the sources alone.