
I worked with Professor Frye and Aaron Mahr this summer to digitize census data from the 1950s and 60s tracking areas of employment in each county in the United States. When accessible this data will be valuable in understanding the development of America post WWII and Great depression. The data will allow us to track the geographic concentration of jobs across America, as well as a shift in the types of jobs. However, as of now this data is only in the form of scanned PDF pages from the physical books they were typewritten in. Hand entering this data is beyond time consuming and costly, so we worked on solutions to automate this process to be as hands off and accurate as possible.
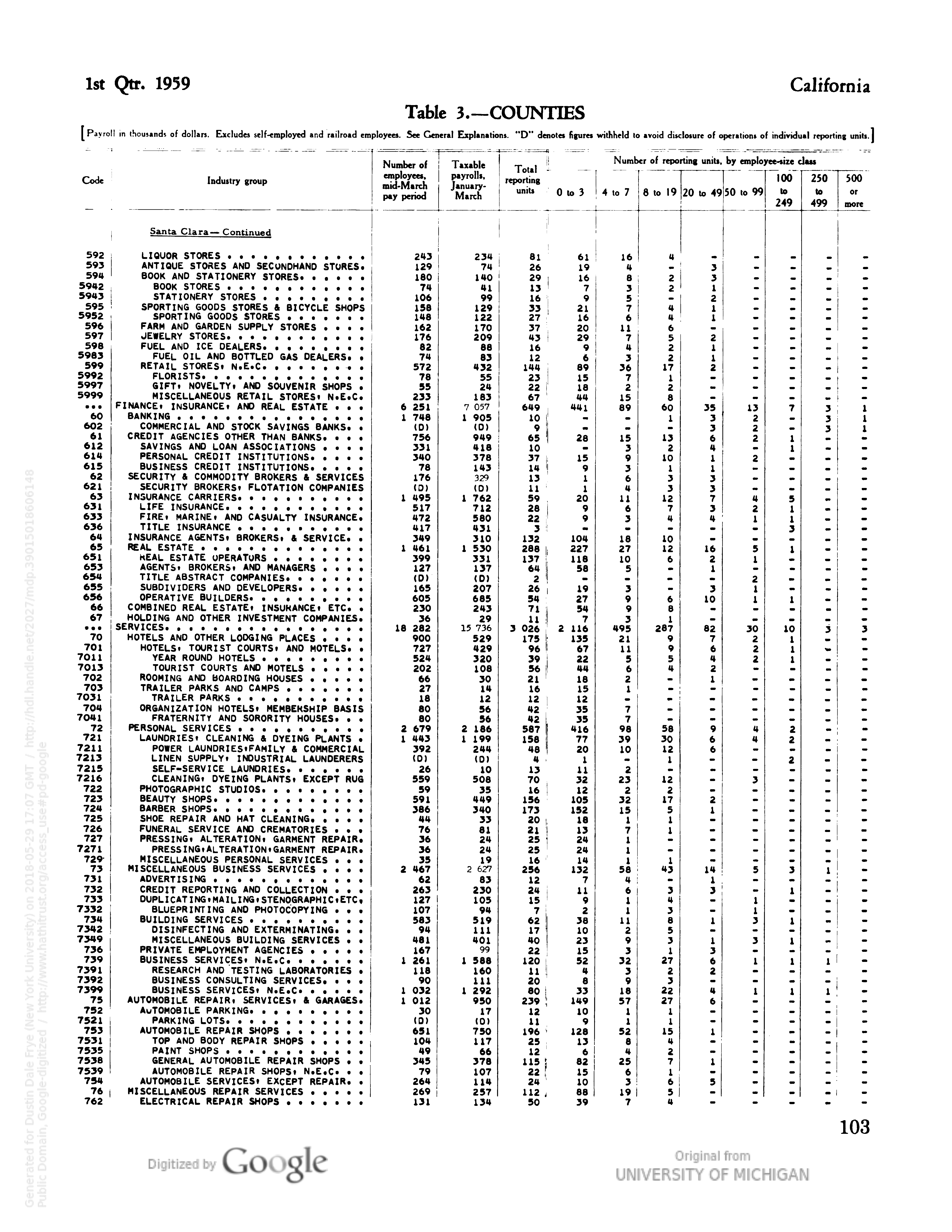
An example of a page we were working to scan.
Using Optical Character Recognition software (OCR), we set out to scan about 4 or 5 years of data, with about 2500 pages per a year. We split the process into developing two different scans of each year, in order to compare later and create one master table. Aaron worked with the Tesseract package in R, while I worked on a process using ABBYY FineReader. Both of these steps posed their own challenges with some overlapping issues. For the ABBYY scan cleaning up places where the scan read poorly or the pages were faded was quite challenging and required some flexibility to design a process to fix or rescan those pages. Additionally we designed a process to use probabilistic matching link the scanned in SIC codes to a master list, making analysis and future table combining much easier.
Working on the project exposed me to the exciting push of research, data cleaning, and development. The process is always improving: working out automated or more linear approaches to previously laborious or confusing steps was very rewarding. Additionally, having the organization needed to plan a multi step process with many pieces was quite eye opening. While we only completed a scan of one year, the steps and processes in place will clear the way to the future scanning of later years.